RAG conecta los LLMs con tus propios datos para respuestas precisas y actualizadas. Así se construyen sistemas de IA fiables en entornos empresariales.


Si últimamente estás escuchando hablar de RAG cada vez que alguien menciona modelos de lenguaje (LLMs) como ChatGPT, Gemini o Claude, no es casualidad. RAG se está convirtiendo en una de las piezas más importantes para llevar la IA del “demo que impresiona” a soluciones realmente útiles en empresas.
¿Te imaginas porqué? motivo es simple: los LLMs son muy buenos generando texto, pero tienen un límite claro en contextos profesionales. Muchas veces responden con información:
Genérica (demasiado amplia o poco accionable)
Desactualizada (porque el modelo no “sabe” lo último que pasó)
o directamente inventada (alucinaciones) cuando no tiene datos fiables
Y si ya es molesto ver cómo se equivoca, en una empresa, eso puede ser un problema real: una respuesta errónea en soporte, una política interna mal citada o un dato comercial equivocado puede costar tiempo, dinero y confianza.
Ahí es donde entra RAG: una forma de hacer que un modelo de lenguaje responda con información real, específica y actualizada, sacada de tus propios documentos o fuentes de datos, sin necesidad de reentrenar el modelo.
Qué es RAG (definición clara y simple)
RAG son las siglas de Retrieval-Augmented Generation, que en español podríamos traducir como generación aumentada por recuperación de información.
RAG es una forma de hacer que un modelo de lenguaje genere respuestas usando información externa y específica, en lugar de basarse solo en lo que “sabe” por su entrenamiento.
Un modelo de lenguaje tradicional (un LLM “solo”) responde a partir de patrones aprendidos durante su entrenamiento. Eso funciona bien para preguntas generales, pero tiene dos límites claros:
No conoce tus documentos internos,
No sabe información reciente o específica de tu negocio.
RAG soluciona esto añadiendo un paso previo: buscar información relevante en una fuente externa (tus datos) y usarla como contexto para generar la respuesta.
Explicado de la manera más sencilla
Imagina dos escenarios:
LLM sin RAG:
Es como un empleado muy inteligente, pero que responde solo con lo que recuerda de memoria.LLM con RAG:
Es ese mismo empleado, pero con acceso en tiempo real a tus documentos, bases de conocimiento y políticas internas, y que los consulta antes de responder.
La diferencia no está en que el modelo sea “más inteligente”, sino en que responde con la información correcta en el momento adecuado.
Diferencia clave entre un LLM “solo” y un sistema con RAG
Aspecto | LLM “solo” (sin RAG) | LLM con RAG |
|---|---|---|
Fuente de información | Conocimiento aprendido durante el entrenamiento | Documentos y datos externos en tiempo real |
Actualización de datos | Limitada al momento del entrenamiento | Puede usar información actualizada sin reentrenar |
Nivel de personalización | Genérico | Adaptado a tu empresa, producto o contexto |
Riesgo de alucinaciones | Medio–alto cuando no tiene datos claros | Mucho menor (se apoya en fuentes reales) |
Uso de información interna | No puede acceder a datos propios | Usa documentación interna y privada |
Fiabilidad en entornos profesionales | Limitada | Alta |
Casos ideales | Preguntas generales, creatividad, brainstorming | Soporte, ventas, RRHH, compliance, documentación |
Un LLM “solo” genera respuestas desde su memoria.
Un LLM con RAG consulta primero tus datos y responde con contexto real.
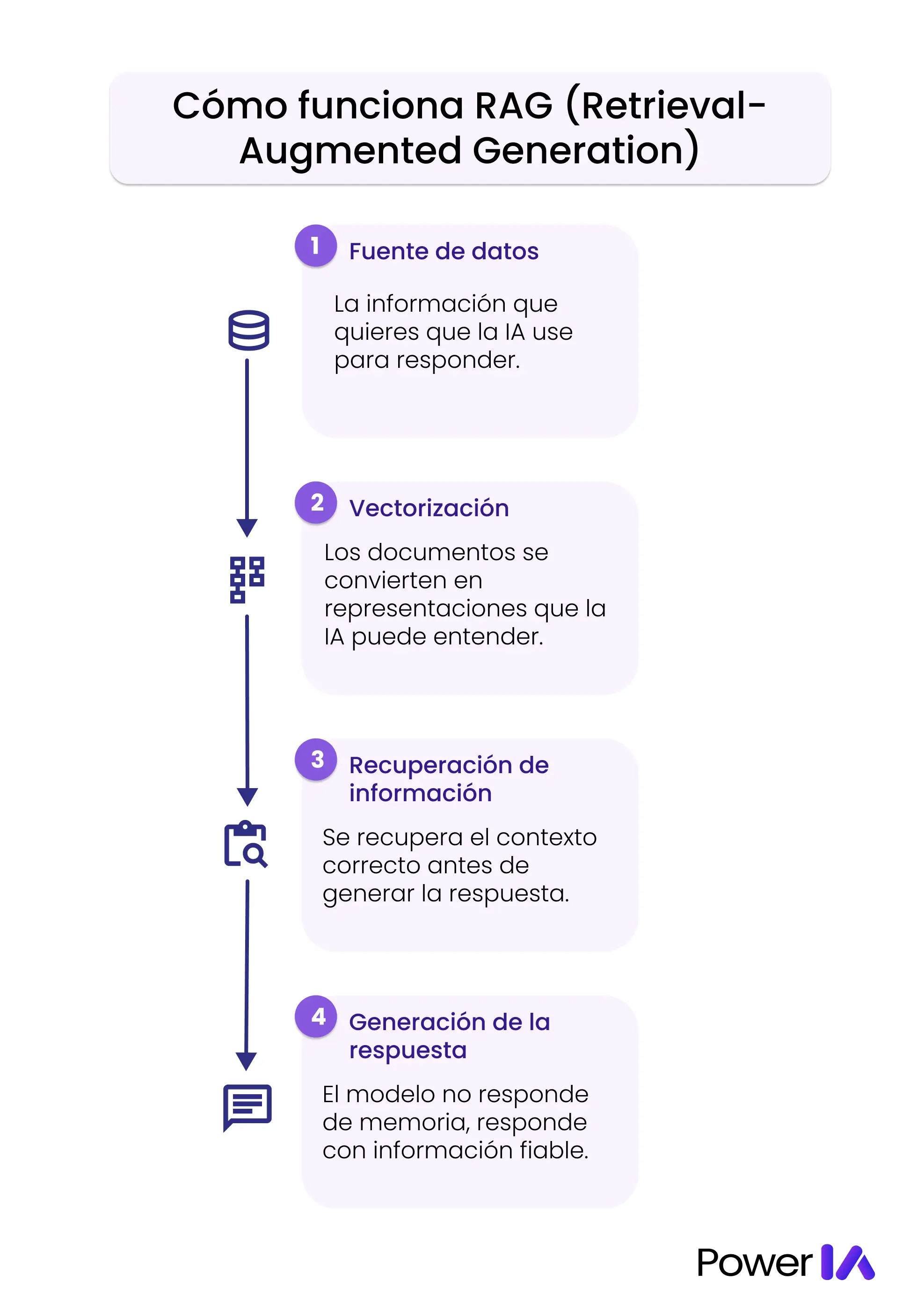
Cómo funciona RAG (paso a paso)
Aunque por dentro RAG es un sistema técnico, su lógica es bastante intuitiva si la ves como un flujo de trabajo. No hace falta saber programar para entenderlo.
Paso 1: Fuente de datos
Todo empieza con la información que quieres que la IA use como referencia.
Normalmente son:
Documentos internos
PDFs
Bases de conocimiento
FAQs
Políticas
Documentación técnica
Información comercial o legal
Clave: RAG no inventa datos nuevos, trabaja con información que tú le proporcionas.
Paso 2: Vectorización (embeddings)
Los documentos no se usan tal cual. Primero se transforman en un formato que la IA pueda “entender”.
De forma simplificada:
El texto se divide en fragmentos
Cada fragmento se convierte en un vector (una representación matemática de su significado)
No necesitas saber cómo funciona matemáticamente; lo importante es entender que la IA puede buscar por significado, no solo por palabras exactas.
Paso 3: Recuperación de información relevante
Cuando un usuario hace una pregunta, el sistema:
Analiza la pregunta
Busca en la base vectorial los fragmentos más relevantes
Selecciona solo la información que realmente tiene sentido para esa consulta
Este es el corazón del RAG: traer el contexto adecuado en el momento justo.
Paso 4: Generación de la respuesta con contexto
Por último, el LLM (ChatGPT, Gemini, Claude, etc.):
Recibe la pregunta del usuario
Recibe también los fragmentos recuperados
Genera la respuesta usando ese contexto como base.
El modelo no responde “de memoria”, sino apoyándose en datos reales y actuales.
RAG = buscar información relevante primero, generar la respuesta después.
Este flujo es lo que hace que RAG sea mucho más fiable que un LLM usado “a pelo”, especialmente en entornos profesionales.
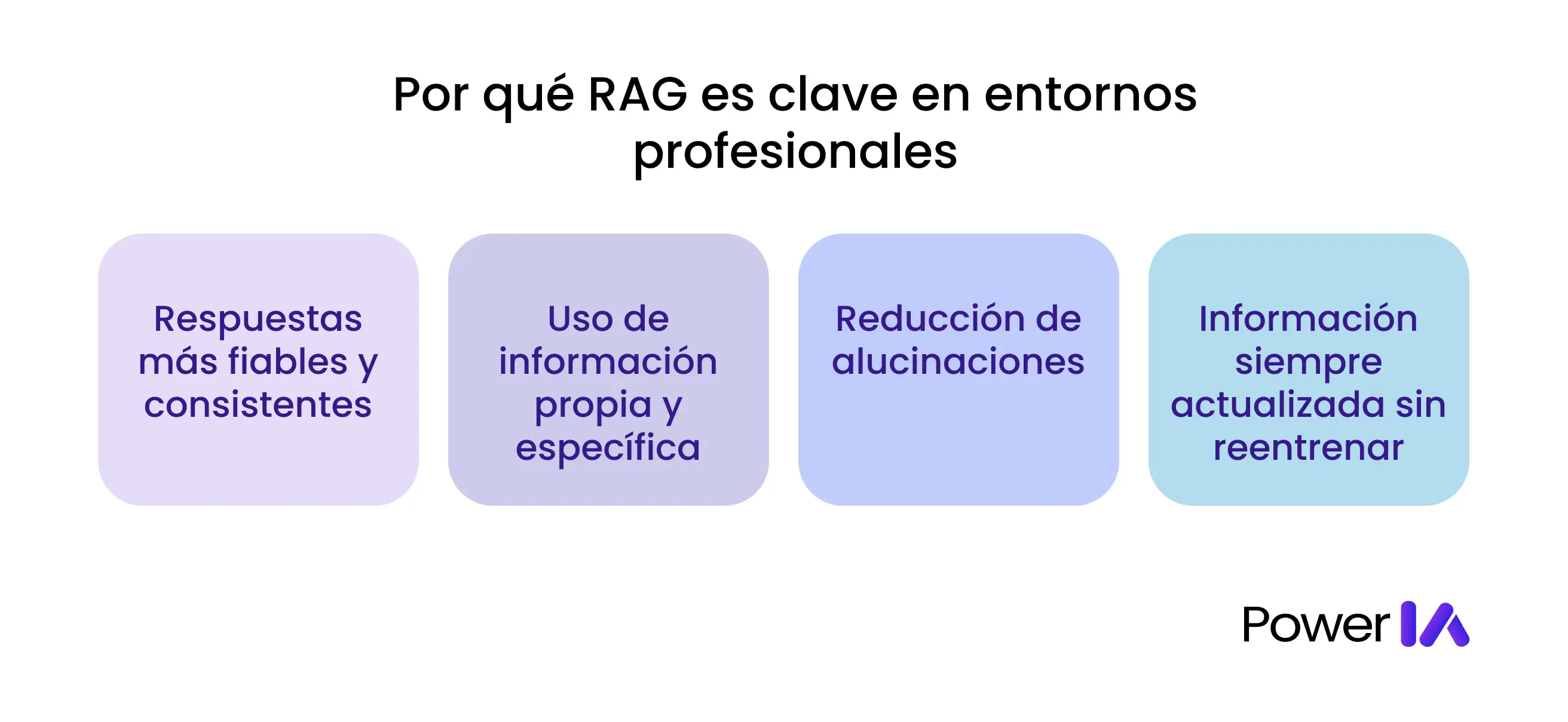
Por qué RAG es clave en entornos profesionales
En entornos empresariales, el problema no es que la IA “no sepa responder”, sino que responde sin el contexto correcto. Y sin contexto, incluso el mejor modelo puede fallar.
RAG es clave porque cambia el orden de las cosas:
Primero recupera la información correcta, luego genera la respuesta.
Ese simple cambio marca una diferencia enorme cuando la IA se usa en procesos reales.
Respuestas más fiables y consistentes
En una empresa, no basta con que una respuesta “suene bien”. Tiene que ser correcta, coherente y repetible.
RAG permite que la IA:
Se base en documentos reales
Use siempre la misma fuente de verdad
Mantenga coherencia entre respuestas
Esto es fundamental en áreas como soporte, RRHH, legal o compliance, donde una respuesta incorrecta puede generar problemas reales.
Uso de información propia y específica
Uno de los grandes límites de los LLMs es que no conocen tu negocio.
No saben cómo funciona tu producto, tus políticas internas ni tus procesos.
Con RAG, la IA puede:
Consultar documentación interna
Usar FAQs corporativas
Responder según tus reglas y procedimientos
Adaptarse a tu contexto específico
La IA deja de ser genérica y empieza a comportarse como alguien “formado dentro de la empresa”.
Reducción de alucinaciones
Las alucinaciones aparecen cuando el modelo no tiene datos claros y “rellena” los huecos.
RAG reduce este problema porque:
El modelo no tiene que inventar
Responde apoyándose en fragmentos reales
Puede incluso citar o justificar la información usada
No elimina el riesgo al 100 %, pero lo reduce drásticamente, especialmente en preguntas operativas o técnicas.
Información siempre actualizada sin reentrenar modelos
Entrenar o reentrenar un modelo es costoso, lento y complejo.
Con RAG:
Basta con actualizar los documentos
Añadir nueva información
Eliminar contenido obsoleto
La IA empezará a responder con esos cambios sin tocar el modelo base. Esto es clave en empresas donde la información cambia constantemente.
RAG vs Fine-Tuning: ¿en qué se diferencian?
Cuando una empresa quiere que un modelo de IA “sepa más”, suelen aparecer dos opciones: RAG o fine-tuning. Aunque a veces se presentan como alternativas similares, resuelven problemas distintos.
Ene sta tabla intentamos dejártelo claro
Aspecto | RAG (Retrieval-Augmented Generation) | Fine-Tuning |
|---|---|---|
Qué hace | Añade contexto externo a cada respuesta | Modifica el comportamiento del modelo |
Tipo de información | Datos y documentos externos | Conocimiento “internalizado” en el modelo |
Actualización de datos | Muy fácil (actualizas documentos) | Compleja (requiere reentrenar) |
Coste | Bajo–medio | Alto |
Tiempo de implementación | Rápido | Lento |
Mantenimiento | Sencillo | Costoso |
Flexibilidad | Muy alta | Baja |
Riesgo de obsolescencia | Bajo | Alto si cambian los datos |
Casos ideales | Documentación, soporte, RRHH, ventas, compliance | Estilo de respuesta, tono, tareas muy específicas |
Errores comunes al implementar RAG
RAG es potente, pero no funciona por sí solo. Cuando los resultados no son buenos, casi nunca es “culpa del modelo”, sino de cómo se ha planteado la solución. Estos son los errores más habituales en entornos reales.
Datos mal preparados o poco claros
RAG depende totalmente de la calidad de los documentos.
Errores frecuentes:
Documentos desactualizados
PDFs mal estructurados
Información duplicada o contradictoria
Textos demasiado largos sin dividir
Si la fuente es confusa, la respuesta también lo será.
No actualizar las fuentes
Uno de los mayores beneficios de RAG es poder actualizar información sin reentrenar modelos. Paradójicamente, muchas empresas olvidan mantener los documentos al día.
Resultado:
Respuestas correctas… pero obsoletas
Pérdida de confianza en el sistema
RAG necesita un proceso de actualización, no solo una implementación inicial.
Prompts mal diseñados
RAG no elimina la necesidad de buenos prompts.
Errores comunes:
No indicar cómo usar el contexto recuperado
No pedir respuestas basadas solo en la información encontrada
No definir tono, formato o nivel de detalle
Un mal prompt puede hacer que el modelo ignore el contexto recuperado.
Esperar “magia” sin una estrategia
RAG no sustituye el pensamiento crítico ni el diseño de procesos.
Errores típicos:
Conectar documentos “a la buena de Dios”
No definir casos de uso claros
No probar ni validar resultados
Asumir que el sistema siempre acertará
RAG funciona mejor cuando hay objetivos claros y expectativas realistas.
RAG es el puente entre la IA genérica y la IA útil en empresa
Los modelos de lenguaje son potentes, pero por sí solos no son suficientes para entornos profesionales. El verdadero salto de valor ocurre cuando la IA deja de responder “de memoria” y empieza a hacerlo con contexto real, datos propios y fuentes verificables.
Eso es exactamente lo que permite RAG.
Gracias a esta arquitectura, las empresas pueden usar IA para:
Responder con información fiable
Aprovechar su propio conocimiento interno
Reducir errores y alucinaciones
Mantener los sistemas actualizados sin reentrenar modelos
Escalar casos de uso reales en soporte, ventas, RRHH o compliance
RAG no consiste en hacer la IA más inteligente, sino en hacerla más útil. Y en el mundo empresarial, utilidad y fiabilidad valen más que creatividad sin contexto.
Si quieres avanzar hacia una IA aplicada, conectada a datos reales y pensada para procesos de negocio, entender RAG ya no es opcional: es parte del nuevo estándar.
FAQs sobre RAG
¿RAG necesita saber programar?
No necesariamente. Aunque la implementación técnica suele requerir perfiles especializados, entender RAG y definir casos de uso no requiere programar. Muchos profesionales trabajan con RAG a nivel funcional y estratégico sin escribir código.
¿RAG sustituye al fine-tuning?
No. RAG y fine-tuning resuelven problemas distintos. RAG se usa para aportar contexto y datos actualizados; el fine-tuning sirve para modificar el comportamiento o estilo del modelo. En la mayoría de casos empresariales, RAG es suficiente.
¿Se puede usar RAG con ChatGPT u otros LLMs?
Sí. RAG no depende de un modelo concreto. Puede utilizarse con distintos LLMs siempre que se puedan combinar con una capa de recuperación de información externa.
¿RAG reduce las alucinaciones de la IA?
Sí, de forma significativa. Al basarse en documentos reales y recuperarlos antes de generar la respuesta, el modelo tiene menos necesidad de “inventar” información.
¿Para qué tipo de empresas tiene más sentido usar RAG?
RAG es especialmente útil en empresas que manejan mucha documentación interna, información sensible o procesos complejos: soporte, atención al cliente, ventas, RRHH, legal, compliance o conocimiento corporativo.
Por:
Equipo Editorial Power IA
·
Fecha de Actualización:
Artículos Relacionados


Automatización de procesos con IA: cómo funciona y qué herramientas usar en 2026
VER ARTÍCULO

Salario de profesionales de IA en España y en remoto: la brecha que cambia la ecuación
VER ARTÍCULO

MCP: qué es el Model Context Protocol y por qué cambia la forma de usar la IA
VER ARTÍCULO

Claude vs ChatGPT: cuál elegir si trabajas en negocio
VER ARTÍCULO

Qué es Claude: la IA de Anthropic que los profesionales necesitan conocer
VER ARTÍCULO

La IA no viene a quitarte el trabajo: viene a multiplicarlo
VER ARTÍCULO